



Nghiên cứu mô hình phát hiện gian lận báo cáo tài chính
Bài viết nghiên cứu về các mô hình phát hiện gian lận báo cáo tài chính của các doanh nghiệp được niêm yết (DNNY) trên Sở Giao dịch chứng khoán Việt Nam trong giai đoạn 2019 - 2021. Kết quả cho thấy, cả 4 mô hình: M - Score, Z - Score, F - Score, P - Score kết hợp với R - Score đều không có mô hình nào phát hiện gian lận báo cáo tài chính hiệu quả, tối ưu đối với các công ty ở Việt Nam đã niêm yết trên Sở Chứng khoán nhà nước
Đặt vấn đề
Hiện nay, gian lận báo cáo tài chính là một vấn đề rất nghiêm trọng đối với các doanh nghiệp, Chính phủ và các nhà đầu tư trên thế giới. Vấn đề này đang ngày càng gia tăng mạnh mẽ, đặc biệt tại các quốc gia có thị trường vốn, gian lận báo cáo tài chính đã đe dọa đến niềm tin của công chúng vào thông tin trên thị trường.
Trên thế giới cũng đã phát hiện nhiều vụ việc gian lận tài chính đặc biệt nghiêm trọng của các công ty lớn như: Enron, Lucent, WorldCom và Satyam,… Các vụ việc gian lận này xảy ra đã gây hậu quả nặng nề cho các đối tượng liên quan, làm suy giảm nghiêm trọng lòng tin của nhà đầu tư trong và ngoài nước. Ảnh hưởng đặc biệt lớn đến uy tín của doanh nghiêp, làm tăng chi phí sử dụng vốn.
Bên cạnh đó, thị trường chứng khoán Việt Nam đã thành lập được gần 20 năm và đóng vai trò quan trọng đối với nền kinh tế Việt Nam. Tuy nhiên, trong những năm gần đây, nhà đầu tư ngày càng lo ngại khi thị trường chứng khoán Việt Nam đã chứng kiến nhiều vụ bê bối liên quan đến việc bất cân xứng thông tin của các công ty niêm yết trên sàn.
Hiện nay, chuẩn mực kiểm toán số 240 (VSA 240) do Bộ Tài chính ban hành, quy định về trách nghiệm của kiểm toán viên liên quan đến gian lận báo cáo tài chính, yêu cầu kiểm toán viên phải đánh giá rủi ro sai sót trọng yếu trên báo cáo tài chính dựa vào các yếu tố động cơ/áp lực, cơ hội và thái độ hoặc khả năng hợp lí hóa (MOF, 2012).
Do đó, đứng về góc độ của nhà đầu tư, chuẩn mực này chưa thực sự hữu ích trong quá trình ra quyết định. Vì vậy, đòi hỏi cần có một nghiên cứu thực tiễn để đưa ra một mô hình dễ dàng tiếp cận và áp dụng hơn đối với các phán đoán về mức độ gian lận báo cáo tài chính.
Mô hình nghiên cứu
Dựa vào các nghiên cứu trước đây, bài viết đưa ra mô hình nghiên cứu như sau:
Mô hình M - Score của Beneish (1999)
Công thức:
M - Score = -4.840+0.920*DSRI + 0.528*GMI + 0.404*AQI + 0.892*SGI + 0.115*DEPI - 0.172*SGAI - 0.327*LVGI + 4.697*TATA
Trong đó:
- Biến phụ thuộc M-Score là Dự đoán khả năng gian lận báo cáo tài chính.
- Các biến độc lập:
+ DSRI là các khoản phải thu đối với chỉ số bán hàng; DSRI = (Các khoản phải thu t/Doanh thu bán hàng và cung cấp dịch vụ t)/(Các khoản phải thu t-1/ Doanh thu bán hàng và cung cấp dịch vụ t-1);
+ GMI là chỉ số tỷ lệ lãi gộp; GMI = Lợi nhuận gộp t/Lợi nhuận gộp t-1;
+ AQI là chỉ số chất lượng tài sản; AQI = [1 - (Tài sản ngắn hạn t + Tài sản dài hạn hữu hình t)/Tổng tài sản t]/[1 - (Tài sản ngắn hạn t-1 + Tài sản dài hạn hữu hình t-1)/Tổng tài sản t-1];
+ SGI là chỉ số tăng trưởng doanh thu bán hàng; SGI = (Doanh thu t/Doanh thu t-1);
+ DEPI là chỉ số tỷ lệ khấu hao; DEPI = [Chi phí khấu hao t-1/(Tài sản dài hạn hữu hình t-1 + Chi phí khấu hao TSCD t-1)]/[Chi phí khấu hao TSCD t/(Tài sản dài hạn hữu hình t + Chi phí khấu hao t)];
+ SGAI là chỉ số chi phí bán hàng và quản lý doanh nghiệp; SGAI = [(Chi phí bán hàng t + chi phí quản lý doanh nghiệp t)/Doanh thu bán hàng và cung cấp dịch vụ t]/[(Chi phí bán hàng t-1 + chi phí quản lý doanh nghiệp t-1)/Doanh thu bán hàng và cung cấp dịch vụ t-1];
+ LEVI là chỉ số đòn bẩy tài chính; LVGI = [(Nợ ngắn hạn t + Nợ dài hạn t)/Tổng tài sản t]/[(Nợ ngắn hạn t-1 + Nợ dài hạn t-1)/Tổng tài sản t-1];
+ TATA là chỉ số biến dồn tích so với tổng tài sản; TATA = [(Lợi nhuận trước thuế t - Dòng tiền từ hoạt động kinh doanh t - Dòng tiền từ hoạt động đầu tư t - Dòng tiền từ hoạt động tài chính t)/Tổng tài sản t].
Mô hình Z - Score của Edward Altman (1968)
Công thức:
Z - Score = 1.2*X1 + 1.4*X2 + 3.3*X3 + 0.6*X4 + 0.999*X5
Trong đó:
- Biến phụ thuộc Z - Score là Điểm số Z mà công ty đạt được;
- Các biến độc lập:
+ X1 là tỷ số vốn lưu động/tổng tài sản; X1 = [(Tài sản ngắn hạn - Nợ ngắn hạn)/Tổng tài sản];
+ X2 là tỷ số lợi nhuận giữ lại/tổng tài sản; X2 = Lợi nhuận sau thuế/Tổng tài sản;
+ X3 là tỷ số lợi nhuận trước lãi vay và thuế/tổng tài sản; X3 = (Lợi nhuận gộp - Chi phí bán hàng - Chi phí quản lý doanh nghiệp)/Tổng tài sản;
+ X4 là Giá trị thị trường của vốn chủ sở hữu/ giá trị sổ sách của tổng nợ; X4 = [Vốn hóa thị trường/Tổng nợ phải trả] = [(Giá hiện tại của cổ phiếu*Tổng cổ phiếu đang lưu hành)/Tổng nợ phải trả];
+ X5 là Tỷ số doanh số/tổng tài sản; X5 = Doanh thu bán hàng và cung cấp dịch vụ/Tổng tài sản.
Mô hình F - Score của Dechow (2011)
Công thức:
F - Score = - 7.893 + 0.790*RSST + 2.518*REC + 1.191*INV + 1.979*SOFTASSETS + 0.171*CASHSALES - 0.932*ROA + 1.029*ISSUE
Trong đó:
- Biến phụ thuộc F - Score là điểm số F mà công ty đạt được.
- Các biến độc lập:
+ RSST là biến liên quan đến chất lượng kế toán dồn tích; RSST = (WC + NCO + FIN)/Tổng tài sản bình quân; WC = (Tài sản ngắn hạn - Tiền - Đầu tư ngắn hạn) - (Nợ ngắn hạn - Vay ngắn hạn); NCO = (Tổng tài sản - Tài sản ngắn hạn - Đầu tư vào Công ty con, công ty liên kết) - (Nợ phải trả - Nợ ngắn hạn - Vay dài hạn); FIN = (Đầu tư ngắn hạn + Đầu tư dài hạn) - (Vay dài hạn + Vay ngắn hạn + Cổ phiếu ưu đãi);
+ REC là biến động phải thu khách hàng; REC = Nợ phải thu khách hàng/Tổng tài sản bình quân;
+ INV là biến động hàng tồn kho; INV = Hàng tồn kho/Tổng tài sản bình quân;
+ SOFTASSETS là Tỷ trọng Softassets/tổng tài sản; SOFTASSETS = (Tổng tài sản - TSCĐ hữu hình - Tiền & các khoản tương đương tiền)/Tổng tài sản
+ CASHSALES là biến động tỷ trọng doanh thu thu được bằng tiền; CASHSALES = [(Doanh thu thuần t - Nợ phải thu khách hàng t)/Doanh thu thuần t ] - [(Doanh thu thuần t-1 - Nợ phải thu khách hàng t-1)/Doanh thu thuần t-1];+ ROA là biến động tỷ suất sinh lời/tổng tài sản; ROA = (Lợi nhuận sau thuế t/Tổng tài sản bình quân t) - (Lợi nhuận sau thuế t-1/Tổng tài sản bình quân t-1);
+ ISSUE là phát hành cổ phiếu trong năm; ISSUE = 1 (Nếu trong có phát hành chứng khoán)/năm.
Mô hình P - Score kết hợp R - Score của Pustylnick (2016)
Công thức:
P - Score = 0,367*X6 + 0,98*X7
R - Score = 0,15*X1 + 0,924*X8
Trong đó:
- Các biến phụ thuộc:
+ P - Score là Điểm số P mà công ty đạt được;
+ R - Score là Điểm số R mà công ty đạt được;
- Các biến độc lập:
+ X6 là Tỷ lệ vốn chủ sở hữu; X6 = Vốn chủ sở hữu/Tổng tài sản;
+ X7 là Tỷ lệ doanh thu tài sản; X7 = Doanh thu từ hoạt động kinh doanh/Tổng tài sản;
+ X8 là Tỷ lệ lợi trước thuế và lãi vay/tổng tài sản; X8 = Lợi nhuận trước thuế và lãi vay từ hoạt động kinh doanh/Tổng tài sản.
Phân tích kết quả nghiên cứu
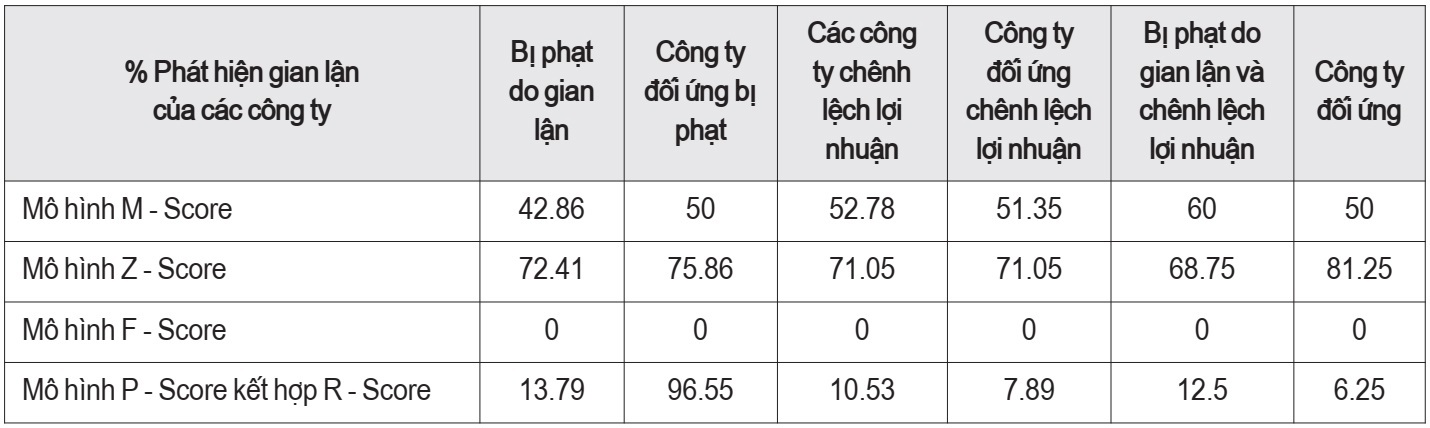
Nhằm tăng tính hiệu quả của các mô hình phát hiện gian lận báo cáo tài chính, nhóm nghiên cứu đã tiến hành chia dữ liệu thành 3 nhóm, đó là: bị phạt, chênh lệch lợi nhuận và vừa bị phạt, vừa chênh lệch lợi nhuận. Kết quả của nghiên cứu đạt được như sau:
Nhóm các công ty bị phạt do gian lận báo cáo tài chính
Kết quả từ số liệu tính toán bởi phần mềm Excel từ 4 mô hình M - Score, Z - Score, F - Score và P - Score kết hợp với Z - Score của các công ty bị phạt do gian lận báo cáo tài chính trong thời gian từ ngày 1/1/2020 đến ngày 31/12/2021 công khai trên Ủy ban Chứng khoán Nhà nước cho thấy, tuy 2 mô hình Z - Score và M - Score có tỷ lệ phát hiện gian lận báo cáo tài chính ở các công ty đã bị phạt rất cao, nhưng khi áp dụng 2 mô hình vào các công ty không bị phạt thì kết quả thu được không hợp lý, không chính xác. Vì vậy, nhóm nghiên cứu nhận định 4 mô hình đều không có tính hiệu quả trong quá trình phát hiện gian lận báo cáo tài chính thông qua nhóm các công ty bị phạt do gian lận báo cáo tài chính.
Nhóm các công ty chênh lệch lợi nhuận trước và sau kiểm toán
Kết quả từ số liệu tính toán bởi phần mềm Excel từ 4 mô hình M - Score, Z - Score, F - Score và P - Score kết hợp với Z - Score của các công ty chênh lệch báo cáo tài chính (Chênh lệch lợi nhuận trước kiểm toán và sau kiểm toán) trong thời gian từ ngày 01/01/2020 đến ngày 31/12/2021 công khai trên Ủy ban Chứng khoán Nhà nước cho thấy chỉ có mô hình Z - Score và M - Score có tỷ lệ phát hiện chênh lệch, gian lận báo cáo tài chính ở các công ty đã bị chênh lệch rất cao, nhưng khi áp dụng 2 mô hình vào các công ty không bị chênh lệch thì kết quả thu được không hợp lý, không chính xác. Vì vậy, nhóm nghiên cứu nhận định, 4 mô hình đều không có tính hiệu quả trong quá trình phát hiện chênh lệch lợi nhuận trên báo cáo tài chính thông qua nhóm các công ty bị chênh lệch lợi nhuận trên báo cáo tài chính.
Nhóm các công ty vừa bị phạt, vừa bị chênh lệch lợi nhuận
Kết quả từ số liệu tính toán bởi phần mềm Excel từ 4 mô hình M - Score, Z - Score, F - Score và P - Score kết hợp với Z - Score của các công ty chênh lệch báo cáo tài chính và bị phạt trong thời gian từ ngày 01/01/2020 đến ngày 31/12/2021 công khai trên Ủy ban Chứng khoán Nhà nước, nhóm tác giả rút ra nhận định tất cả 4 mô hình đều không hiệu quả trong quá trình phát hiện gian lận báo cáo tài chính. Tuy là, mô hình Z - Score, M - Score có tỷ lệ phát hiện gian lận báo cáo tài chính ở các công ty đã bị chênh lệch rất cao, nhưng khi áp dụng 2 mô hình vào các công ty vừa không bị phạt vừa không bị chênh lệch thì kết quả thu được không hợp lý, không chính xác. Vì vậy, nhóm nghiên cứu nhận định, 4 mô hình đều không có tính hiệu quả trong quá trình phát hiện gian lận trên báo cáo tài chính thông qua nhóm các công ty bị gian lận trên báo cáo tài chính.
Kết quả 4 mô hình của các nhóm công ty mà nhóm đã nghiên cứu và đạt được thể hiện tại Bảng 1.
Bảng 1. Bảng kết quả bốn mô hình của các nhóm công ty
Kết luận
Bài nghiên cứu tìm hiểu các mô hình phát hiện gian lận báo cáo tài chính, xem xét tính hiệu quả, tính chính xác của các mô hình. Kết quả nghiên cứu cho thấy cả 4 mô hình đều không có tính hiệu quả, không tối ưu đối với các công ty được niêm yết trên sàn chứng khoán Việt Nam.
Tuy đề tài của nhóm đã đi ngược lại với tất cả đề tài nghiên cứu trước, nhưng nhóm nghiên cứu đã sử dụng những lý thuyết giải thích hành vi gian lận trên thế giới kết hợp với chuẩn mực VSA 240 của Bộ Tài chính để đưa ra lý thuyết tổng hợp về hành vi gian lận, qua đó tạo cơ sở để xây dựng, kiểm định và thử nghiệm các mô hình có khả năng nhận diện gian lận, từ đó đưa ra kết quả về tính hiệu quả của các mô hình.
Một số giải pháp kiến nghị
Các nhà nghiên cứu trong tương lai nên vận dụng hoặc kết hợp các phương pháp phát hiện gian lận báo cáo tài chính trên thế giới để xây dựng thêm nhiều mô hình phát hiện gian lận chính xác hơn và có độ tin cậy cao hơn.
Trong quá trình kiểm toán, kiểm toán viên cần phải mạnh dạn xem xét báo cáo tài chính có khả năng gian lận hay không bằng nhiều phương pháp phát hiện gian lận khác nhau, không nên chỉ dựa vào chuẩn mực kiểm toán hoặc dựa trên kinh nghiệm, hoặc dựa vào chạy các mô hình phát hiện gian lận.
Để giảm thiểu rủi ro các nhà đầu tư cần phải trang bị cho mình những kiến thức vững vàng về thị trường, về kinh tế, tài chính và kiến thức về kế toán. Đặc biệt phải có kiến thức về các phương pháp phát hiện gian lận báo cáo tài chính để tự mình phát hiện ra những thông tin bất thường.
Sở Giao dịch chứng khoán TP. Hồ Chí Minh sẽ đề xuất với cơ quan có thẩm quyền về việc áp dụng hình thức chế tài mạnh hơn nữa, chẳng hạn như xử lý hình sự đối với các công ty vi phạm để răn đe mạnh cho các công ty còn lại.
Tài liệu tham khảo:
- Bộ Tài chính, (2012). Thông tư số 214/2012/TT-BTC về Ban hành Hệ thống chuẩn mực kiểm toán Việt Nam.
- Chuẩn mực kiểm toán số 240: Trách nhiệm của kiểm toán viên liên quan đến gian lận trong quá trình kiểm toán báo cáo tài chính.
- Võ Minh Dương, (2016). Sử dụng mô hình Beneish M-Score đánh giá chất lượng BCTC ở Việt Nam. Luận văn thạc sĩ, Trường Đại học Kinh tế TP. Hồ Chí Minh.
- Altman, E. I. (1968). Financial ratios, discriminant analysis and the prediction of corporate bankruptcy. The Journal of Finance, 23(4), 589-609.
- Beneish, M. D. (1999). The detection of earnings manipulation. Financial Analysts Journal, 55(5), 24-36.
- Dechow, P. M., Ge, W., Larson, C. R. and Sloan, R. G. (2011). Predicting Material Accounting Misstatements. Contemporary Accounting Research, 28(1), 17-82.
- Score, K. M. B. (2016). Detecting financial statement fraud by Malaysian public listed companies: The reliability of the Beneish M-Score model. Jurnal Pengurusan, 46, 23-32.

















